January 15, 2018
Literature Computer Analysis: An Example
Before the development (let alone the use) of a tool, first comes the identification of its need; its scope, in other words. As an academic with research interests revolving around the Gothic and science fiction, and with some rudimentary programming experience, I had a crazy idea. Most great ideas come as a result of madness and boredom, I suppose, and my idea was one just like that. What if, I thought, I made a simple program that could detect certain patterns in Gothic and science fiction? In other words, what if I made a literature computer analysis program that could help me create a taxonomy of the texts I’m researching?

The Basics of Using a Computer to Analyze a Text
Thanks to my education, I had a solid theoretical idea of what it was I had to look for. The challenge was to come up with a way to tell the computer to scan the novel I’d given it and report back. In all honesty, the whole thing began almost as a joke. “Hey, let’s make a computer program that tells you if a text is Gothic!” Never would I imagine that… it would actually happen. The program became so complex, deep, and far-reaching, that it began showing me things I hadn’t even thought about.
One problem that did remain was that the computer analysis program doesn’t really… analyze. It only gives you the data. It still takes a human (indeed, one with literature education) to interpret the results. And so, at least for now, I thought to keep the program for personal use and not distribute it. I still use this literature computer analysis little program as an invaluable tool for a quick breakdown of a text. In today’s article I’ll show you a few of the things it does to help me.
Since this whole thing began almost as a joke, I really did think to start with the Holy Grail of Gothic studies: how can you tell if a text is Gothic or not? I started simply by telling the program (written in JavaScript, by the way) to scan the book for certain keywords. Obviously enough, if a text contains words such as “vampire”, “ghost”, “werewolf”, that’s a good start. But only a start. It’s not only a matter of which words exist in a text, but also of how they are used, in what combinations, as well as in which context – just to name three examples. I’ll spare you the details of what else I asked the computer analysis program to look for (hey, I should keep some professional secrets too, right? *wink wink*) and just tell you that it worked. It actually worked!
The program gave really high marks on all the classic Gothic works I tried it with, and very low on the control texts. Intriguingly, it also wasn’t fooled by Jane Austen’s Northanger Abbey, which was written as a parody of Gothic novels. To give you a few numbers, the program gave Dracula 81%, Frankenstein 83%, Pride and Prejudice (one of the control texts) 8%, and Northanger Abbey 25%. That’s impressive.
A Thematic Analysis
At this point I began to realize that I could really do it: I could create a literature computer analysis code. And so, I began implementing several other things that would be useful in the process of analyzing a text. The first was a category chart, that would show the origin of the score for the text in question. I was interested to see, what gave most of the points to each Gothic work. Was it the element of fear, the sublime, settings, or what?
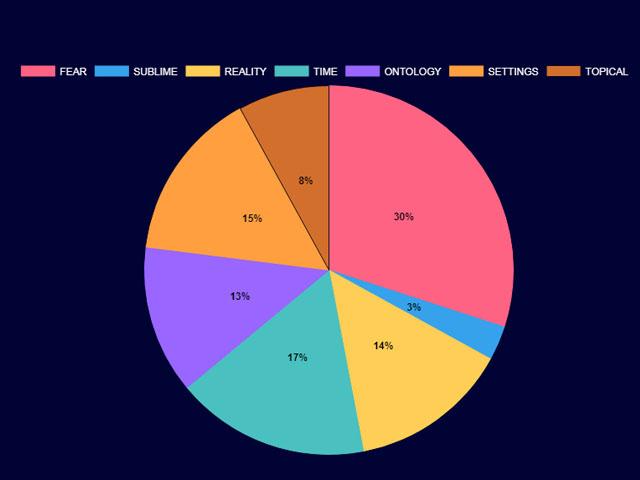
The next step was to see the progression of each element through the narrative. This proved to be trickier to implement, but where there is a will, there is a way. Now I could tell whether Dracula (in our example) uses more fear in the beginning and the end of the narrative (it does), and temporal elements in the middle (indeed). Take a look at the graph below:
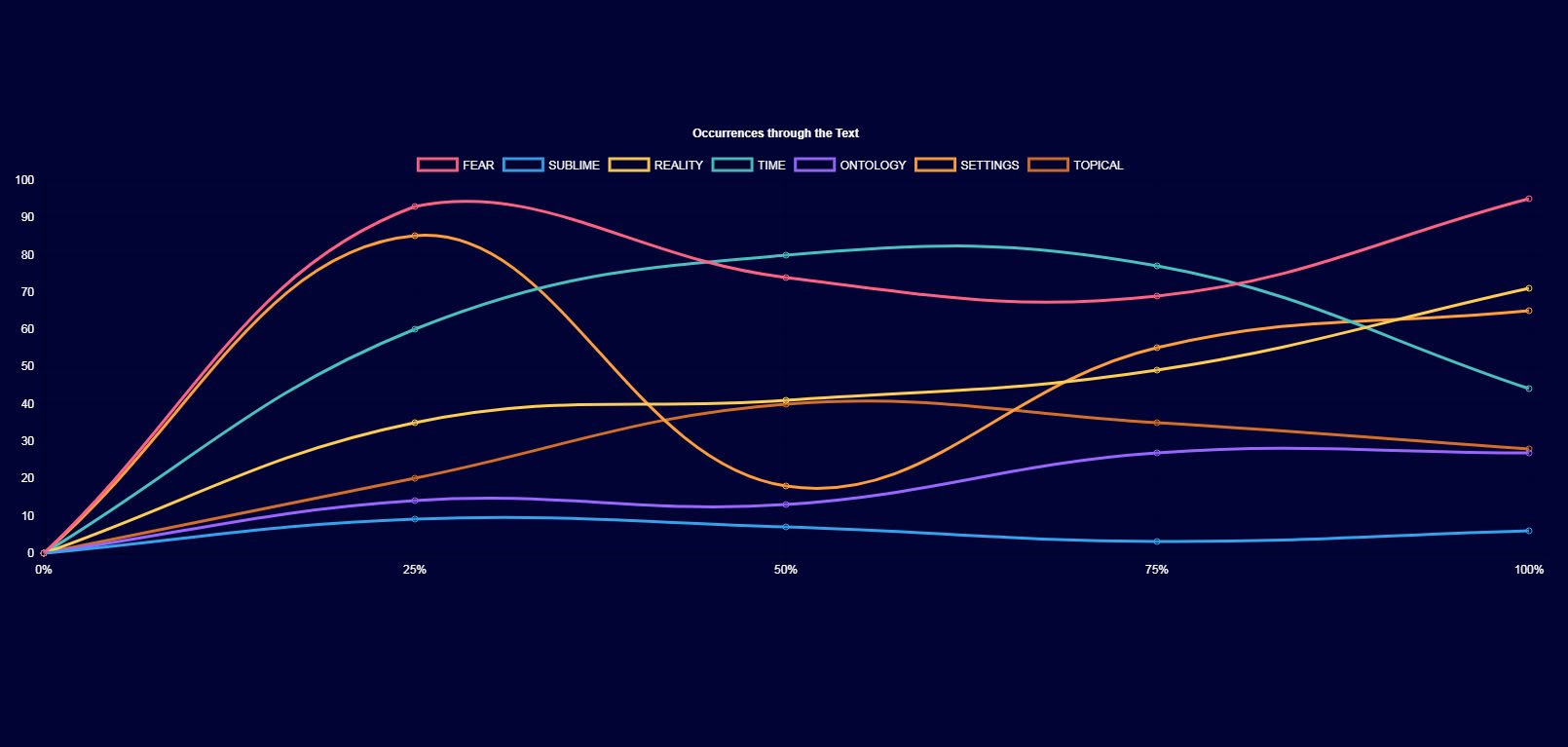
How Can Computer Analysis Help a Novel?
Of course this is the crux of the matter. Graphs and numbers are good and nice, but there has to be a graspable way of using the data to improve things. A literature computer analysis is a tool, not the destination. Here’s where knowledge, experience, and expertise (yours truly, in other words) enter the picture. If I see that a horror novel has a descending “Fear” curve, that’s a problem. Ideally, you want to see something like the one above, for Dracula: a strong, suspenseful beginning, followed by a milder middle phase, and culminating in a rising finale.
Of course, these are only two parts of the program. Among other things, I have developed a way to measure how stereotypical a given text is. As a genre writer (that is, a Gothic, horror, or science fiction writer), you want a certain degree of stereotyping, but depending on certain circumstances. The program I’ve developed helps me evaluate such elements.
I don't show you ads, newsletter pop-ups, or buttons for disgusting social media; everything is offered for free. Wanna help support a human internet?
(If you'd like to see what exactly you're supporting, read my creative manifesto).
